LLM Benchmarking Service
Know exactly how your model performs. We provide comprehensive, multi-dimensional benchmarking with detailed reports comparing your model against baselines and competitors.
Get Started
What is LLM Benchmarking?
LLM Benchmarking is the systematic evaluation of a language model's capabilities across multiple dimensions. It goes far beyond simple accuracy metrics - we assess reasoning, language understanding, code generation, safety, factual knowledge, instruction following, and domain-specific performance.
Our benchmarking service uses both established public benchmarks (MMLU, HumanEval, MT-Bench, etc.) and custom evaluation suites tailored to your specific use case. We provide detailed reports with actionable insights on where your model excels and where it needs improvement.
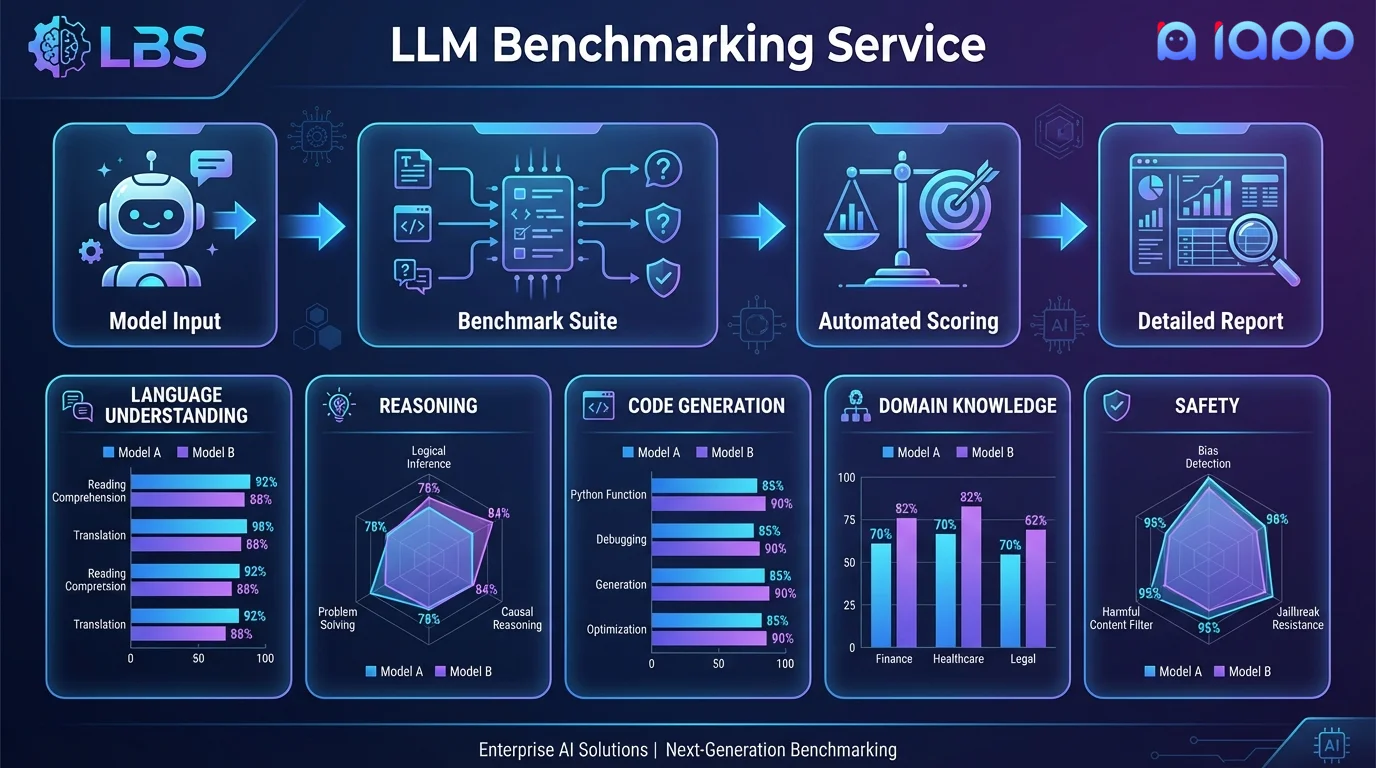
Evaluation Dimensions
We evaluate your model across all critical dimensions
Reasoning & Logic
Mathematical reasoning, logical deduction, common sense reasoning, and multi-step problem solving using GSM8K, MATH, ARC, and custom reasoning tasks.
Language Understanding
Reading comprehension, text classification, sentiment analysis, NER, and summarization using MMLU, HellaSwag, and domain-specific benchmarks.
Code Generation
Code completion, bug fixing, code explanation, and test generation using HumanEval, MBPP, and real-world coding challenges.
Safety & Alignment
Toxicity detection, bias evaluation, refusal accuracy, jailbreak resistance, and content safety using TruthfulQA, BBQ, and red-teaming suites.
Thai Language Proficiency
Thai reading comprehension, Thai cultural knowledge, Thai-English translation quality, and Thai writing style using our proprietary Thai benchmark suite.
Domain-Specific Tasks
Custom evaluation suites for your specific domain - legal, medical, financial, customer service, or any specialized application.
Mathematics
Arithmetic, algebra, calculus, and word problem solving evaluated with GSM8K, MATH, SVAMP, and custom mathematical reasoning benchmarks.
World Knowledge
Factual knowledge across science, history, geography, current events, and culture using TriviaQA, NaturalQuestions, and multi-domain knowledge tests.
How It Works
Rigorous evaluation from design to delivery
Scope Definition
Define evaluation objectives, select benchmark suites, and identify comparison baselines
Test Design
Design custom evaluation tasks specific to your use case alongside standard benchmarks
Automated Evaluation
Run comprehensive automated evaluations across all dimensions on our GPU infrastructure
Human Evaluation
Expert human evaluators assess subjective quality, fluency, and helpfulness
Report Delivery
Receive a detailed report with scores, comparisons, visualizations, and actionable recommendations
Use Cases
Data-driven decisions for your AI strategy
Model Selection
Compare multiple models (open-source, commercial, or custom) on your specific tasks to choose the best one for your deployment.
Finetuning Validation
Measure the improvement from finetuning against the base model baseline. Ensure finetuning hasn't degraded other capabilities.
Regression Testing
Continuously evaluate your model after updates to catch performance regressions before they reach production.
Compliance Certification
Generate evidence for regulatory compliance showing your model meets safety, fairness, and accuracy standards.
Cost-Performance Analysis
Compare model quality against inference cost to find the optimal price-performance tradeoff for your production budget and quality requirements.
Vendor Evaluation
Objectively evaluate LLM providers and vendors with standardized benchmarks on your actual data before committing to a contract.
Why Choose iApp Technology?
Thailand's leading AI company with proven LLM expertise
World-Class Infrastructure
We operate NVIDIA H100, B200, and GB200 supercomputers. Running comprehensive benchmarks on large models requires significant compute, and our infrastructure delivers fast turnaround.
Proven Track Record
We are the makers of production LLMs trusted by enterprises across Thailand and Southeast Asia. We benchmark our own models rigorously.
Pricing
Project-Based Pricing
Benchmarking pricing depends on the number of models being evaluated, benchmark scope, inclusion of human evaluation, and custom task development.
- ✓ Free initial consultation and scope definition
- ✓ Standard + custom benchmark suites
- ✓ Detailed comparison reports with visualizations
- ✓ Actionable improvement recommendations